About Articulatory Speech Synthesis
During the last few decades, advances in computer and speech technology increased the potential for speech synthesis of high quality. Currently, the most successful approach for speech generation in the commercial sector is concatenative synthesis. Concatenative synthesizers store segments of natural speech, which are pieced together to form the desired speech output. The best speech quality is currently achieved by so called unit-selection synthesizers. However, all concatenative synthesizers depend on the prerecorded speech material, which can only be modified moderately without a loss of quality. This makes it difficult to simulate arbitrary voices speaking arbitrary languages and to express emotions like happiness or anger.
One alternative to concatenative synthesizers is the direct simulation of the principles of speech production. This method is called articulatory speech synthesis and has the potential to simulate all aspects of speech production. However, speech production is a very complex process and not fully understood in every detail.
"The speech wave is the response of the vocal tract filter system to one or more sound sources. This simple rule, expressed in the terminology of acoustic and electrical engineering, implies that the speech wave may be uniquely specified in terms of source and filter characteristics" (Fant, 1960).
This statement was made in Fant's fundamental book "Acoustic theory of speech production" and since then has been the foundation for both formant synthesizers and articulatory synthesizers.
Formant synthesizers specify directly the formant frequencies and bandwidths as well as the source parameters.
Articulatory synthesizers, on the other hand, determine the characteristics of the vocal tract filter by means of a description of the vocal tract geometry and place the potential sound sources within this geometry.
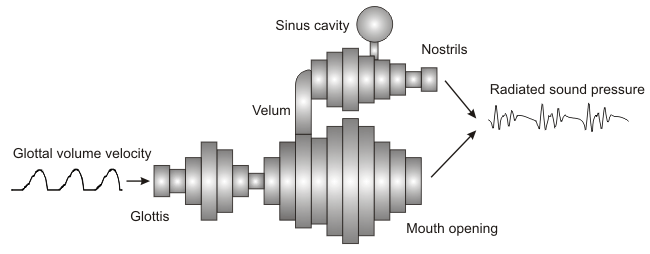
Depending on the synthesizer, the vocal tract geometry is described in one, two or three dimensions.
A one-dimensional model represents the vocal tract directly by means of its area function.
The area function describes how the cross sectional area of the vocal tract tube varies between the glottis and the mouth opening.
Assuming one-dimensional sound propagation in the vocal tract, the area function contains all information to specify the filter characteristics.
Therefore, with regard to the acoustic simulation, the two and three-dimensional vocal tract models are also finally transformed into a one-dimensional area function.
The advantage of these higher-dimensional models is, however, that the form and position of the articulators can be specified in a very direct fashion.
The artificial articulators of such models are usually controlled by means of a small set of articulatory parameters.
The variation of these parameters in time allows the area function of the vocal tract to change during an utterance.
An acoustic model is used to calculate the speech wave from the sequence of area functions with the corresponding sound sources.
In summary, an articulatory synthesizer comprises at least the following three parts:
- a geometric description of the vocal tract based on a set of articulatory parameters
- a mechanism to control the parameters during an utterance
- a model for the acoustic simulation including the generation of the sound sources
For more details about articulatory speech synthesis please also have a look into the manual (and the publications cited there) of the latest VocalTractLab version that you can download from this website.
